
Published December 13, 2021 | Japanese
12/13(月)は、SOC アナリスト 野村和也の記事です。機械学習と可視化による分析手法の紹介です。
---
はじめに
こんにちは!SOCアナリストの野村です。新卒で今春よりSOCに着任しました。現在はSOC業務でアナリストとして生の脅威を分析しながら、日々サイバーセキュリティの勉強を続けております。
弊社のSOCでは多くのお客様環境から大量に発せられるアラートを分析し、その裏に潜む真の脅威をお客様に日々通知しています。弊社のアナリストが公開している記事[1][2]のように、SOCで分析するログの量は膨大であり、その中から真の脅威を過不足なく見つけなければいけません。
一方、近年はビッグデータという言葉をよく聞きますが、膨大な量のデータは新たなナレッジの宝庫です。可視化を通じてデータの大域的な特徴を把握することで、直感や勘が働き、膨大な量のデータに対して深い分析や洞察をすることができます。
また、このような膨大なデータの特徴を掴むために、可視化は非常に効果的です。例えばSOCでは24時間365日体制での監視を行なっていますが、同じアナリストがログを24時間/365日見続けるわけではありません。シフトで休みだった時にどのようなインシデントをどのくらい通知したか、どのようなナレッジが新たに収集されたかなど効率よく共有するために、可視化は非常に重要です。
今回は公開されている脅威情報について、実際にPython (Pandas[3]) による可視化と分析の例を紹介します。また、おまけで、機械学習での分類を試みます。
今回取り上げるデータ
TwitterなどのSNSやフォーラムなど、有志による様々なコミュニティで脅威情報が活発に共有・投稿されています。それらのナレッジを活かすことはSOCにおいてもとても重要です。今回はabuse.ch[4]が提供するThreatfox[5]に投稿されたIOC情報を取り上げます。Threatfoxは比較的近年開設された脅威情報共有のコミュニティですが、IOC情報が非常に高頻度かつ明確な情報とともに共有されています。また、過去に投稿されたIOC情報は全てCSV/JSON形式でダウンロード可能であり、REST APIも提供されています。
今回はその中でも、過去に投稿されたマルウェア感染後の通信先のIPアドレスとポート番号情報が掲載されているデータ[6]について分析を試みます。
今回ダウンロードした22,618件のデータのカテゴリには、マルウェアのダウンロード先を示す「`payload_delivery`」と、感染後のC2通信を示す「`botnet_cc`」の二つのカテゴリがありました。しかし、前者は88件と情報が少ないので、今回の分析ではC2通信を示す「`botnet_cc`」22,530件を取り上げます。
報告されているファミリの情報
今回のデータでは非常に扱いやすいデータで、データのフォーマットがよく揃っています。また、紐づくマルウェアファミリの情報なども明確です。どのようなマルウェアが報告されているかみてみましょう。
今回はぐりぐり動かすことのできるpythonのグラフ可視化ライブラリ「Plotly」[7]を用います。
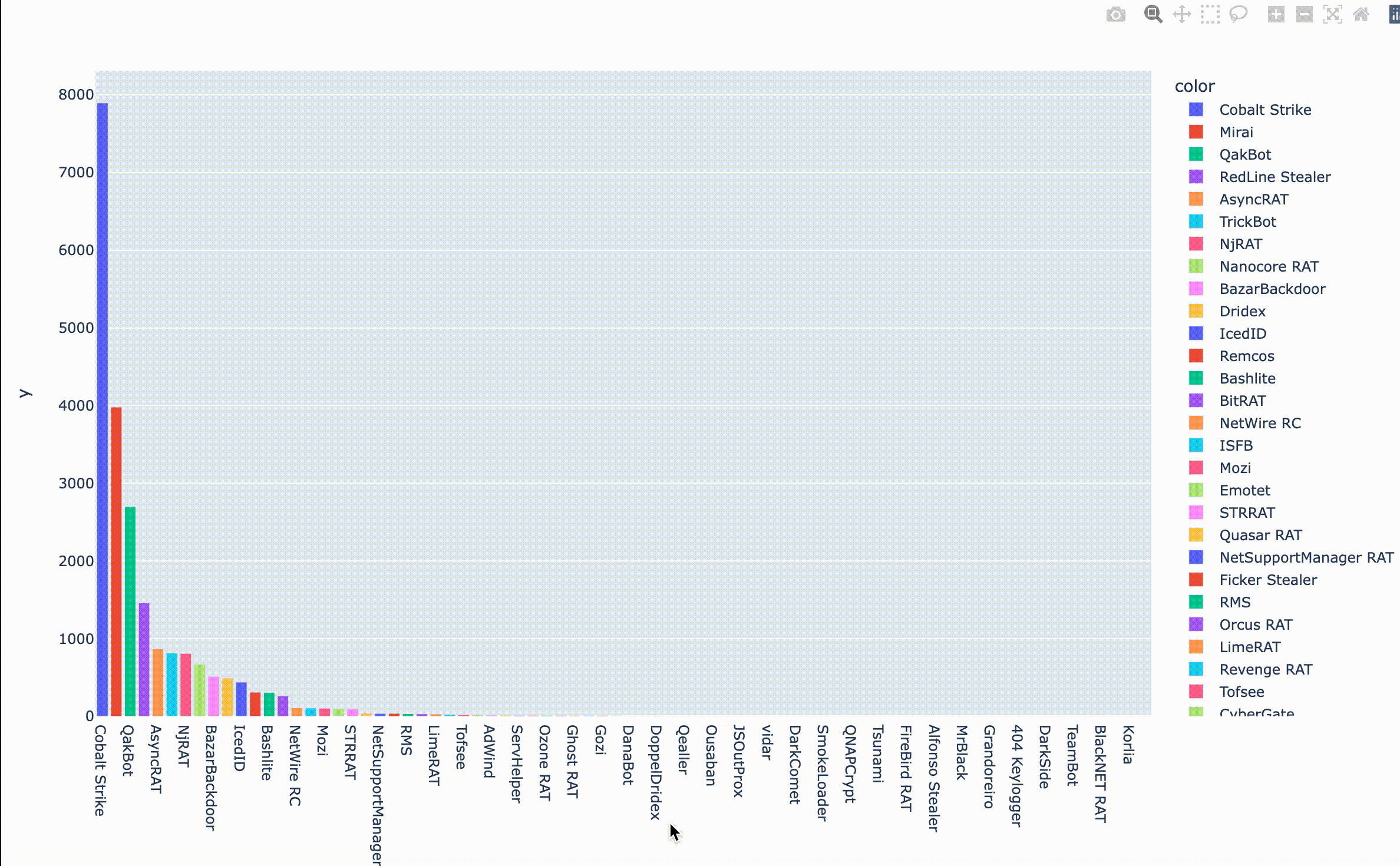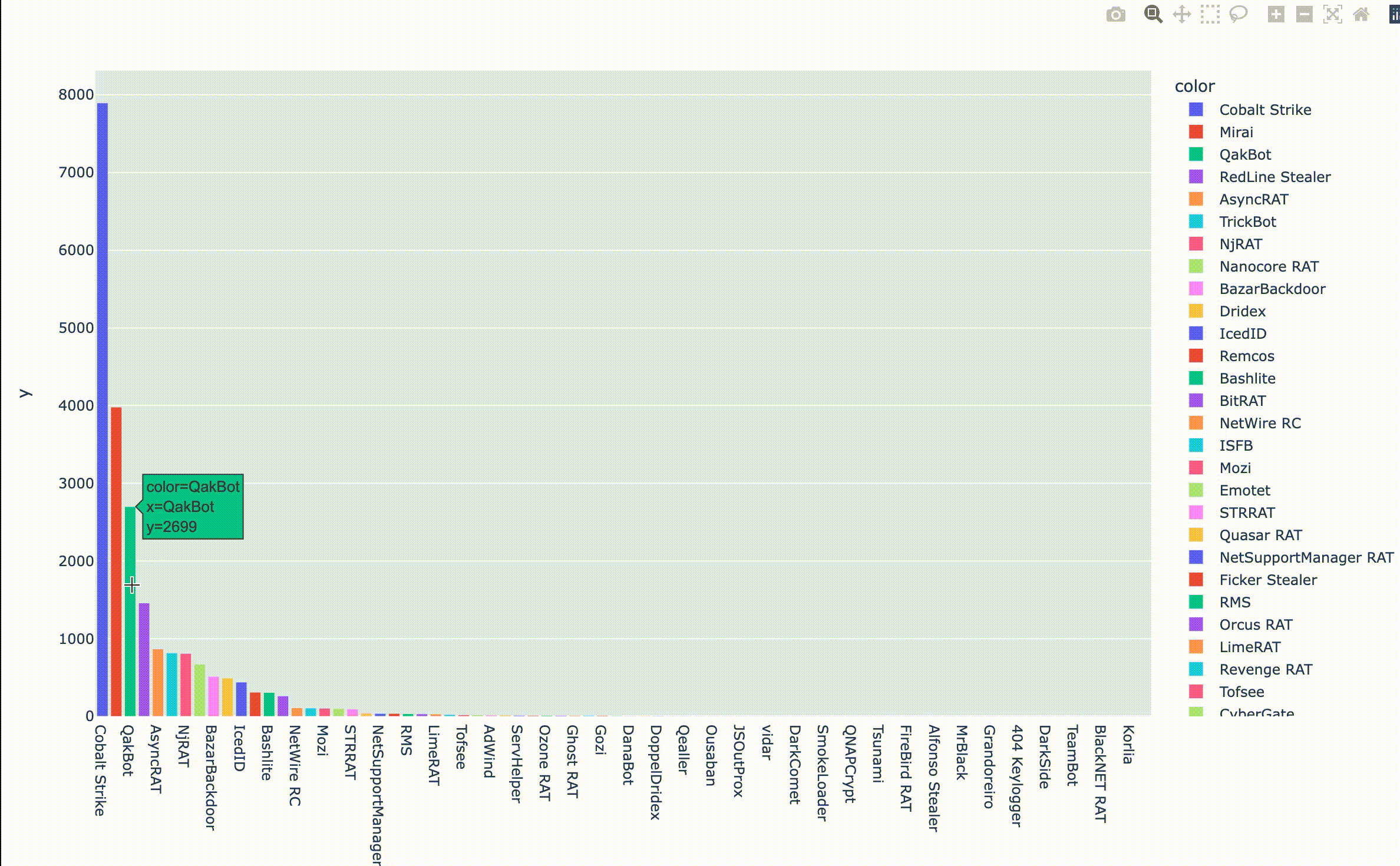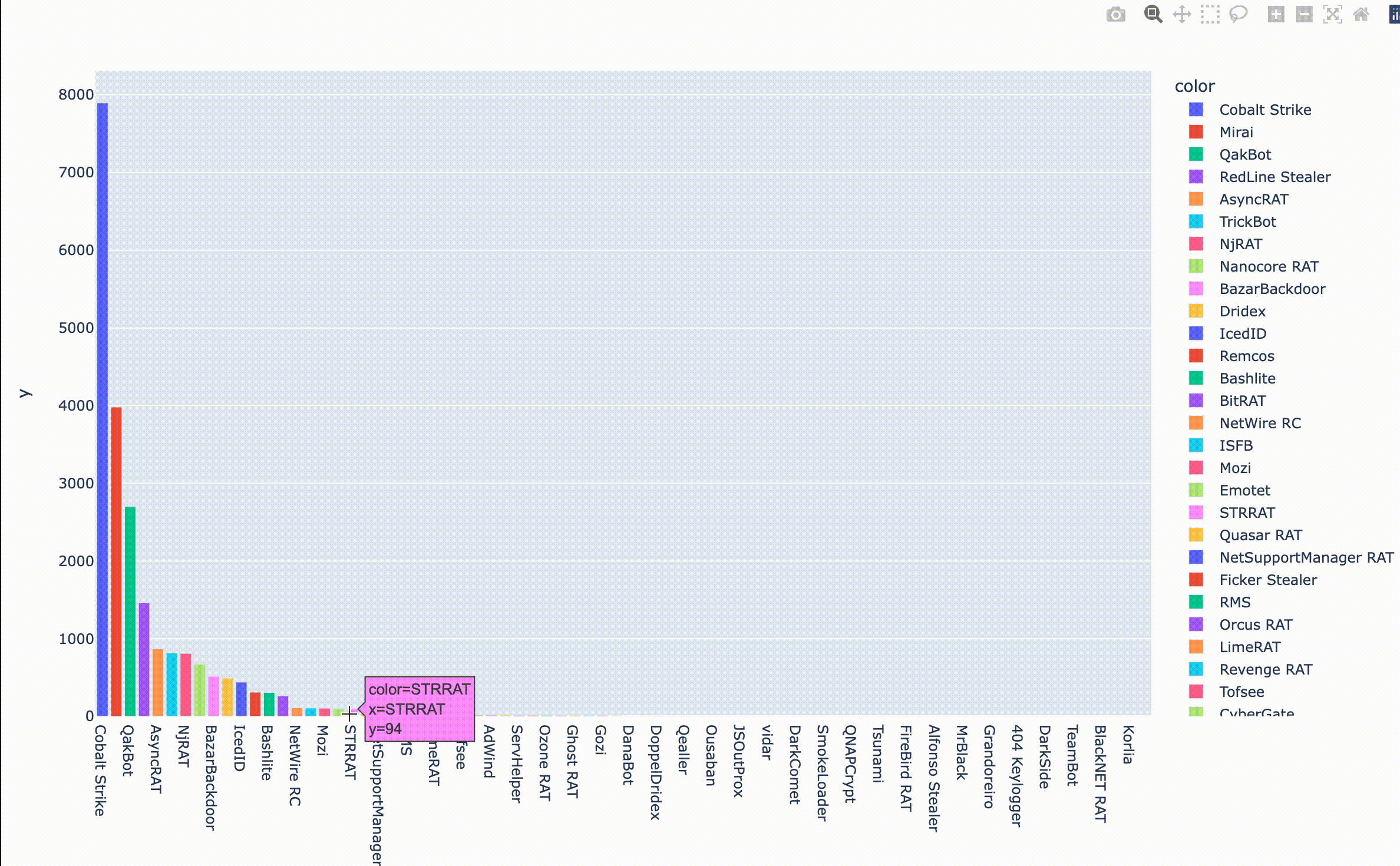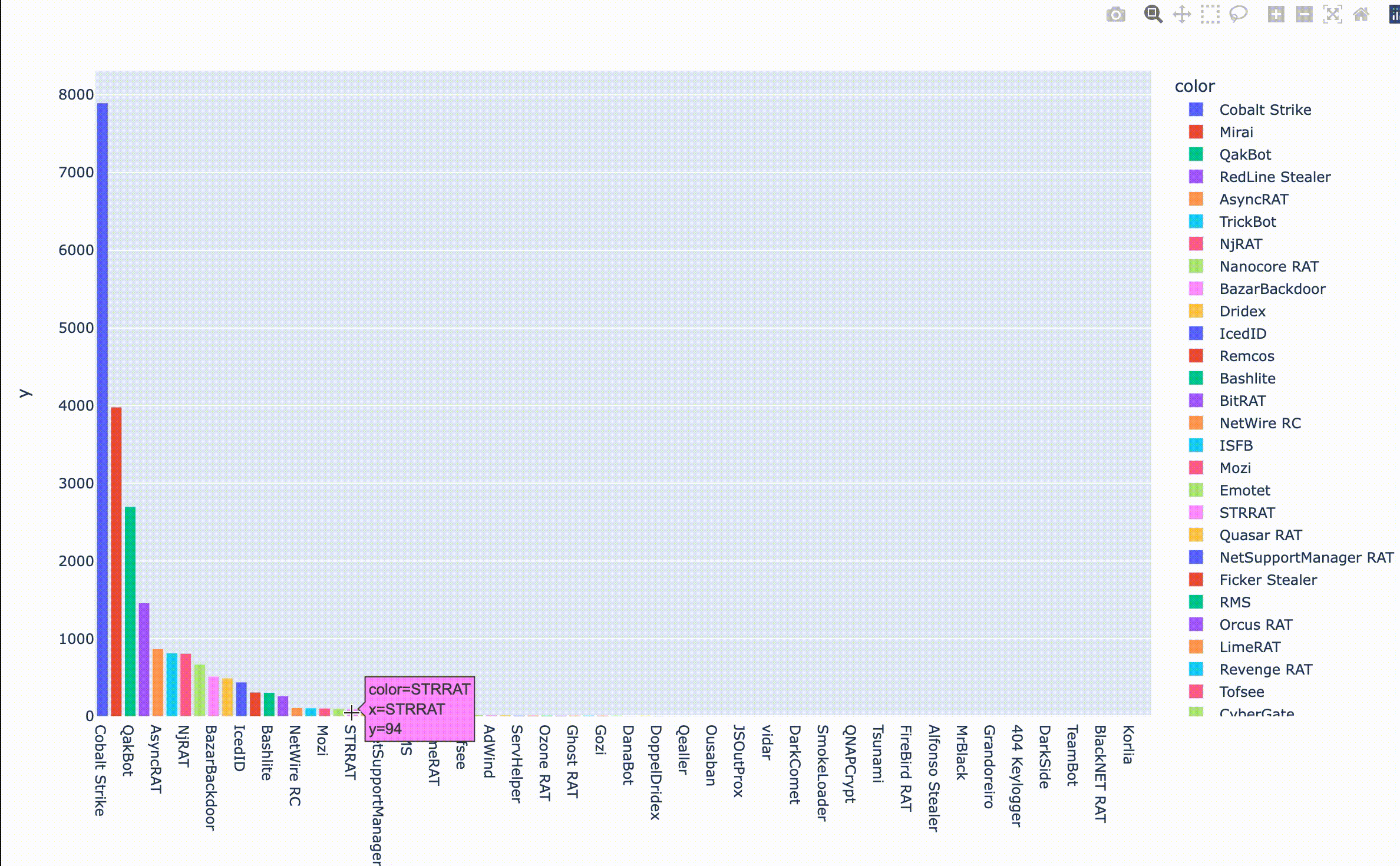
縦軸はIOCの投稿数、横軸は紐づくファミリを示します。見覚えのある名前がずらりと並んでいますね。最近復活したと話題のEmotetもいるようです。Emotetの投稿数が100件ちょっとなので、今回はIOCの投稿数が100件以上のファミリについて分析を進めてみたいと思います。
投稿数の推移
サイバーセキュリティはトレンドが日々変化するため、時系列での分析が重要になります。「何月何日に、あるマルウェアファミリがどのくらい投稿されたか」という集計もPandasでは簡単にできますし、Plotlyでおしゃれに可視化できます。
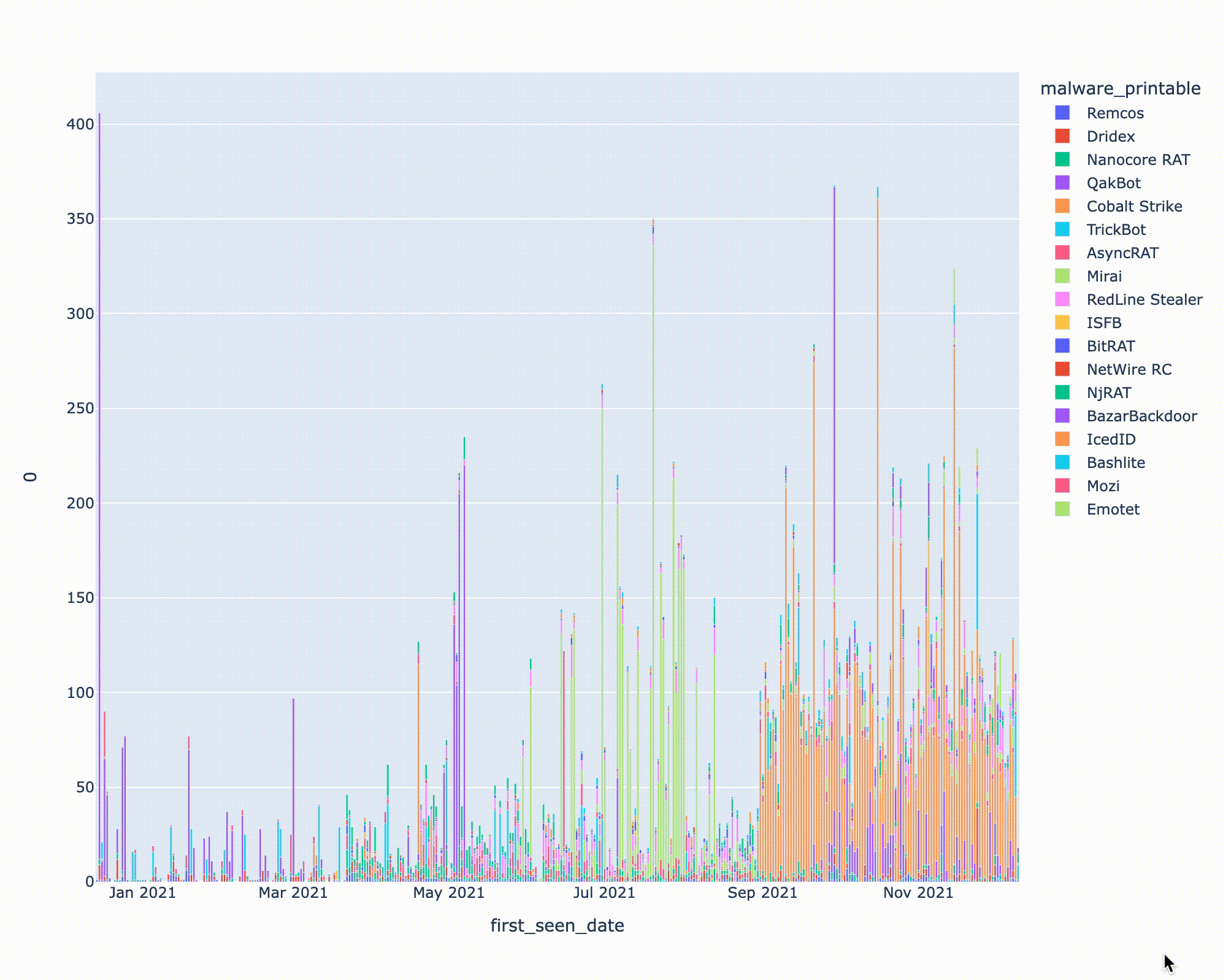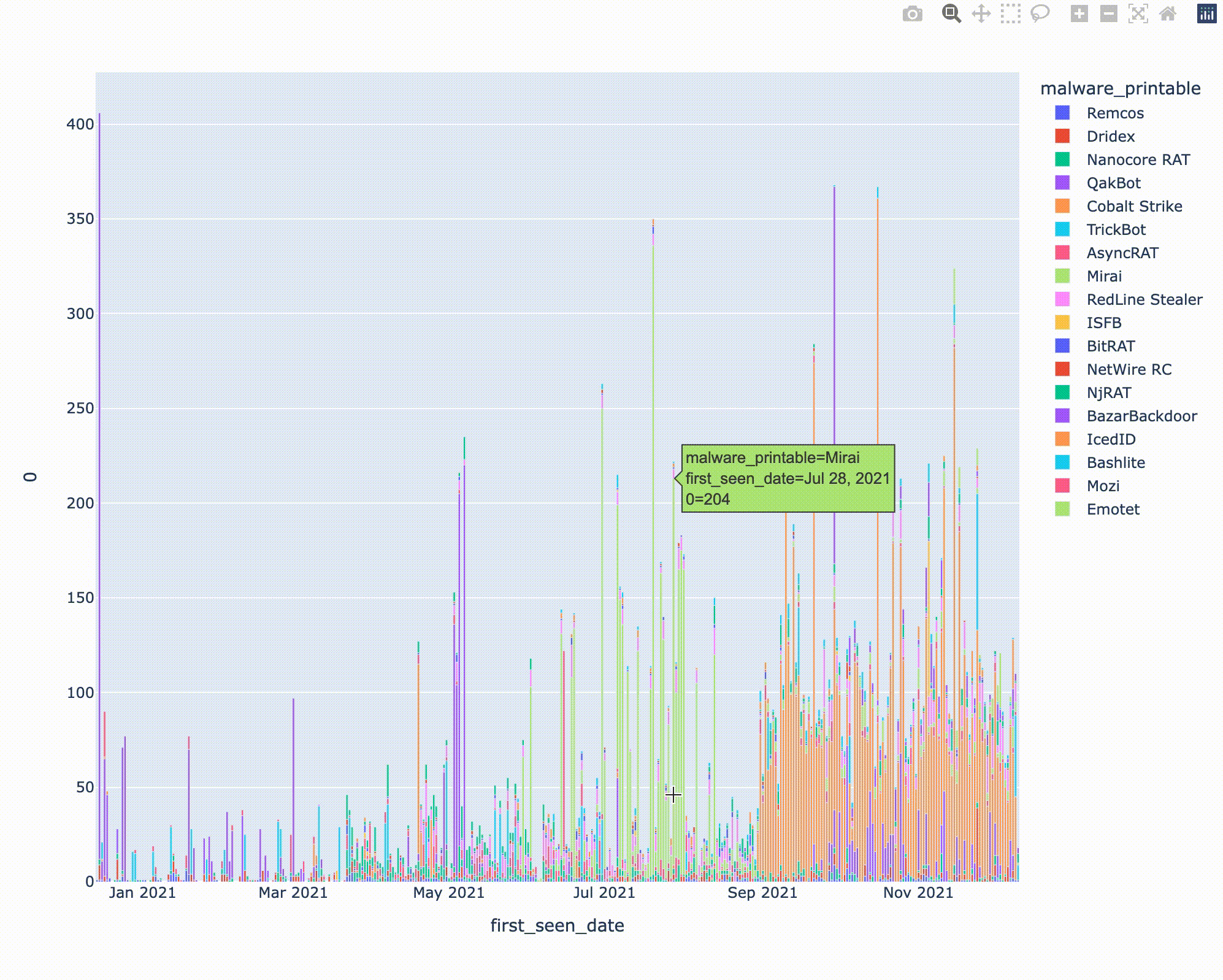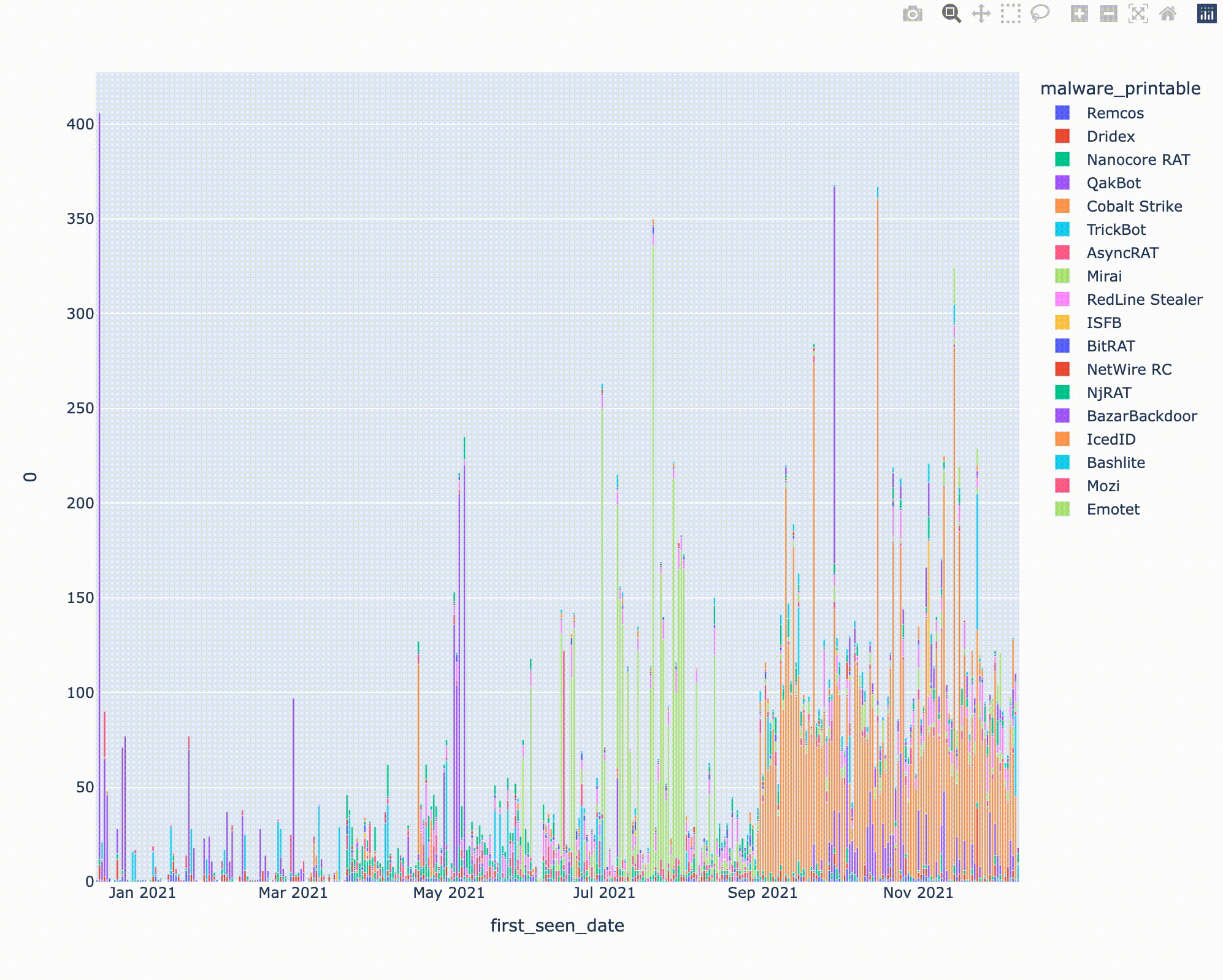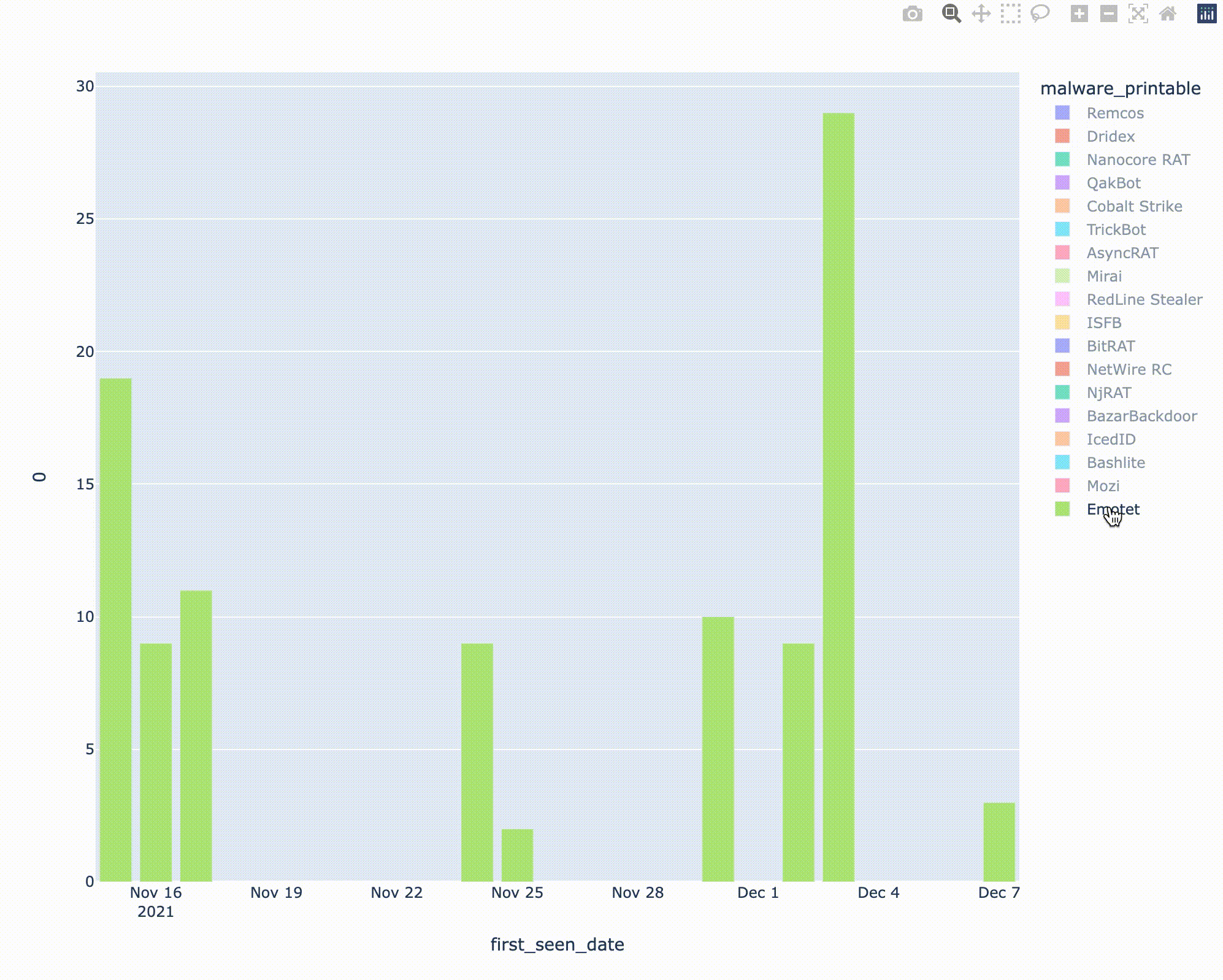
縦軸はIOCの投稿数、横軸は日付を示します。ColaltStrikeの検体が9月ごろから大量に投稿されているのが気になりますが、データを確認したところあるCobaltStrikeのハンターが9月ごろから精力的にThreatFoxへの投稿を始めたことと関係していそうでした。一方、Emotetは11月中ごろに復活したことで話題になりましたが、Threatfoxにも11/15頃からIOC情報の投稿がされていたようです。
ちなみに、abuse.chはFeodo系のbotnetマルウェアのC2を共有する「FeodoTracker」[8]というプラットフォームも提供しているのですが、そちらにもEmotetのC2情報があります。こちらを可視化すると、2021年春先頃のtakedownから期間を空けて、2021年初冬からのEmotetの活動再開の様子を観測することができます。
ポート番号の分布
通信先情報の一つとして重要な意味を持つ、通信先ポート番号の分布を示します。縦軸はIOCの報告数、横軸はポート番号です。これをファミリごとに色分けしてみると下図のようになります。
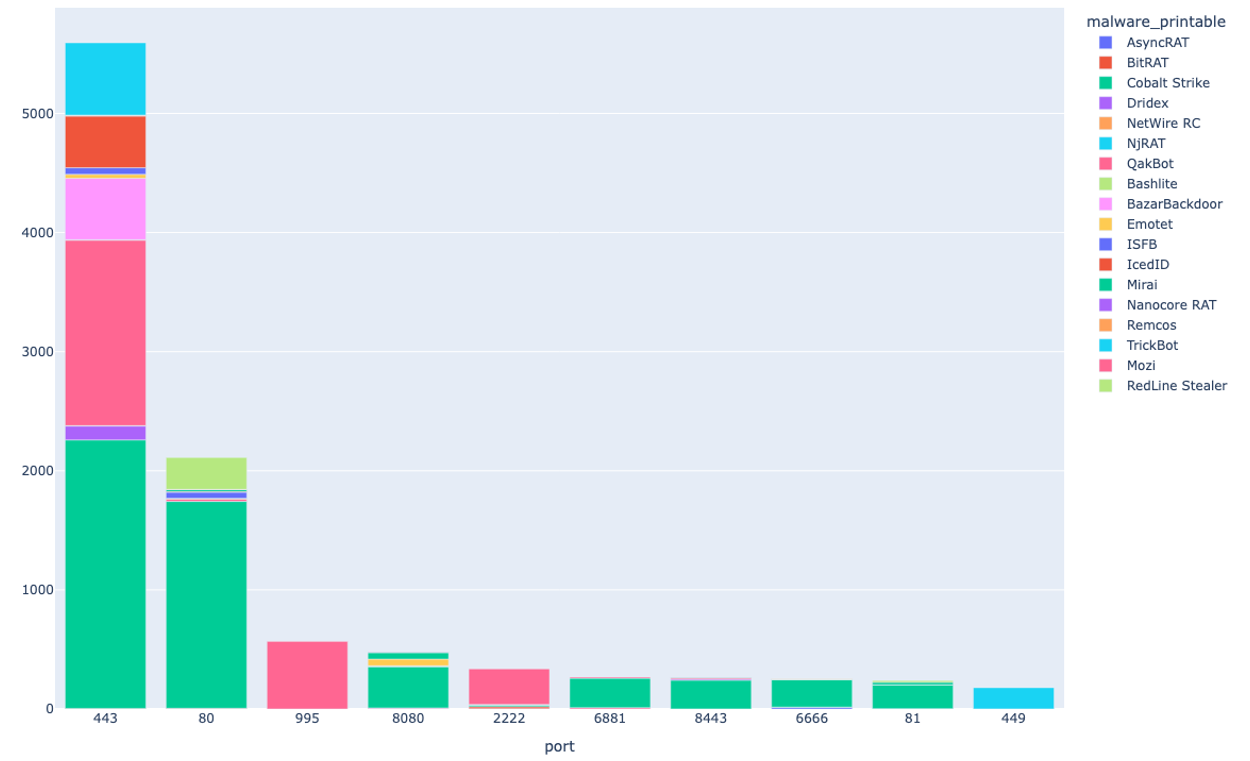
C2通信なので怪しまれないようにわざわざ変なプロトコルを使わず、HTTPっぽいポート番号が多いですね。特に昨今のマルウェアはHTTPS通信を使うことが一目瞭然です。一方で、ポート995、449などが気になります。これはどのようなマルウェアファミリなのでしょうか。
ポート995はPOP3です。そして、マルウェアファミリ「QakBot (Qbot) 」が多く分布していていることがわかります。実際にQbotの感染後にはEメール関連のトラヒックが発生するのが特徴として知られています。また、ポート449にはTrickbotが多く分布しています。こちらもTrickbotの感染後通信の特徴として、ポート449宛のHTTP(S)通信が発生することが知られており、弊社ブログのレポートでも紹介されています。[9][10]
IPアドレスの重複
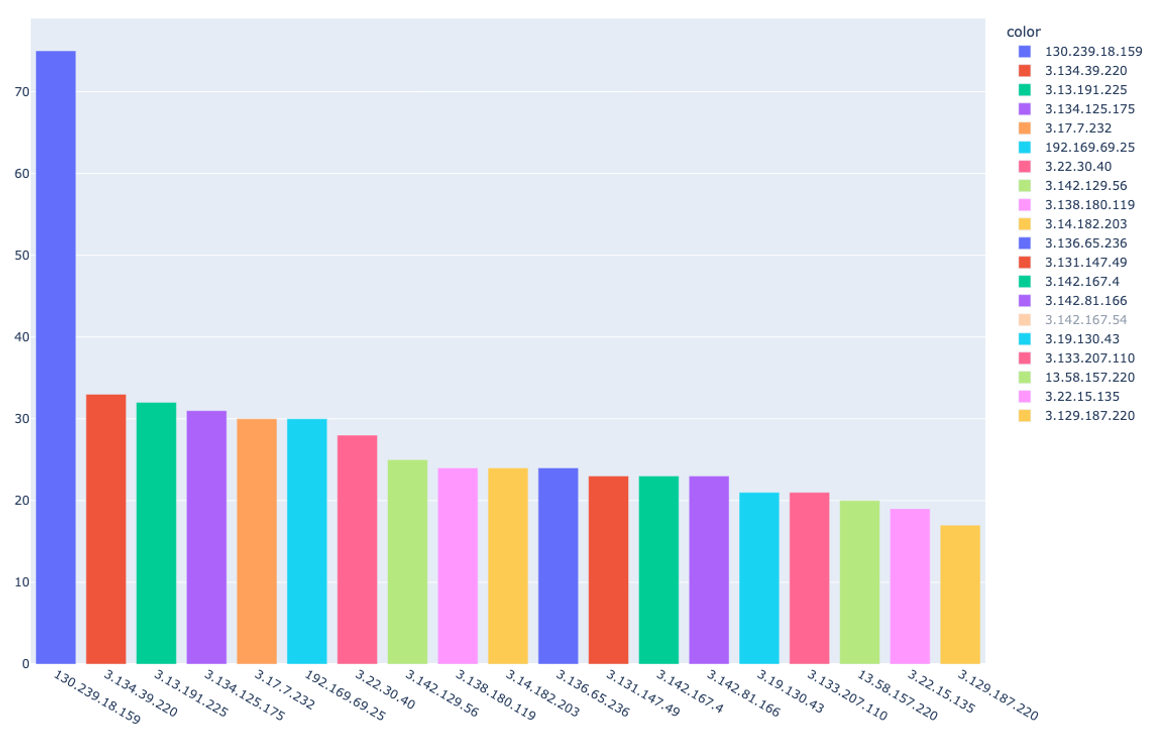
悪性活動に使われるIPアドレスは、使い回される可能性があります。また、IPアドレス同士の関連からマルウェアファミリ間の関連が示唆されることもあります。報告されているIPアドレスの重複を調べると、以下のようになりました。
ダントツで多い130.で始まるIPアドレスはmiraiに大量に紐ついていました。mirai (mozi) は独自のP2Pネットワークを形成し、感染を拡大します。このIPアドレスは調査の結果moziにハードコードされているIPアドレスとしての情報があり、torrentのピアノードという情報もありました。
一方、3.で始まるIPアドレスがずらっと並んでいるのが気になります。このIPアドレスを保持するASはAmazonです。また、それぞれpassive DNSを引くと、意外にも*.ngrok.ioが紐づいているものが多くありました。ngrokはローカルで動いているサービスをフォワーディングして、手軽に外部公開できるサービスです。CTFで使われることも多いのでご存じの方もいるかもしれません。[11]
情報の追加
純粋に集めたデータを可視化しただけでも、以上のようなファミリごとの面白い特徴がわかりました。一方で、IPアドレスからはもう少し情報を得ることができそうです。IPアドレスからは、そのアドレスを提供するISPやAS、また大雑把な所在地がわかるIP Geolocation情報を得ることができます。Pandasを使ってPythonで分析を行うメリットとして、このような外部データを気軽に参照して情報を追加できることが挙げられます。今回はip-api.com[12]が提供するREST APIを用いて、上記の情報を入手しました。
Plotlyは地図上での可視化も容易にできます。取得した緯度、経度情報をファミリ毎に色分けして地図上にプロットすると、以下のようになります。
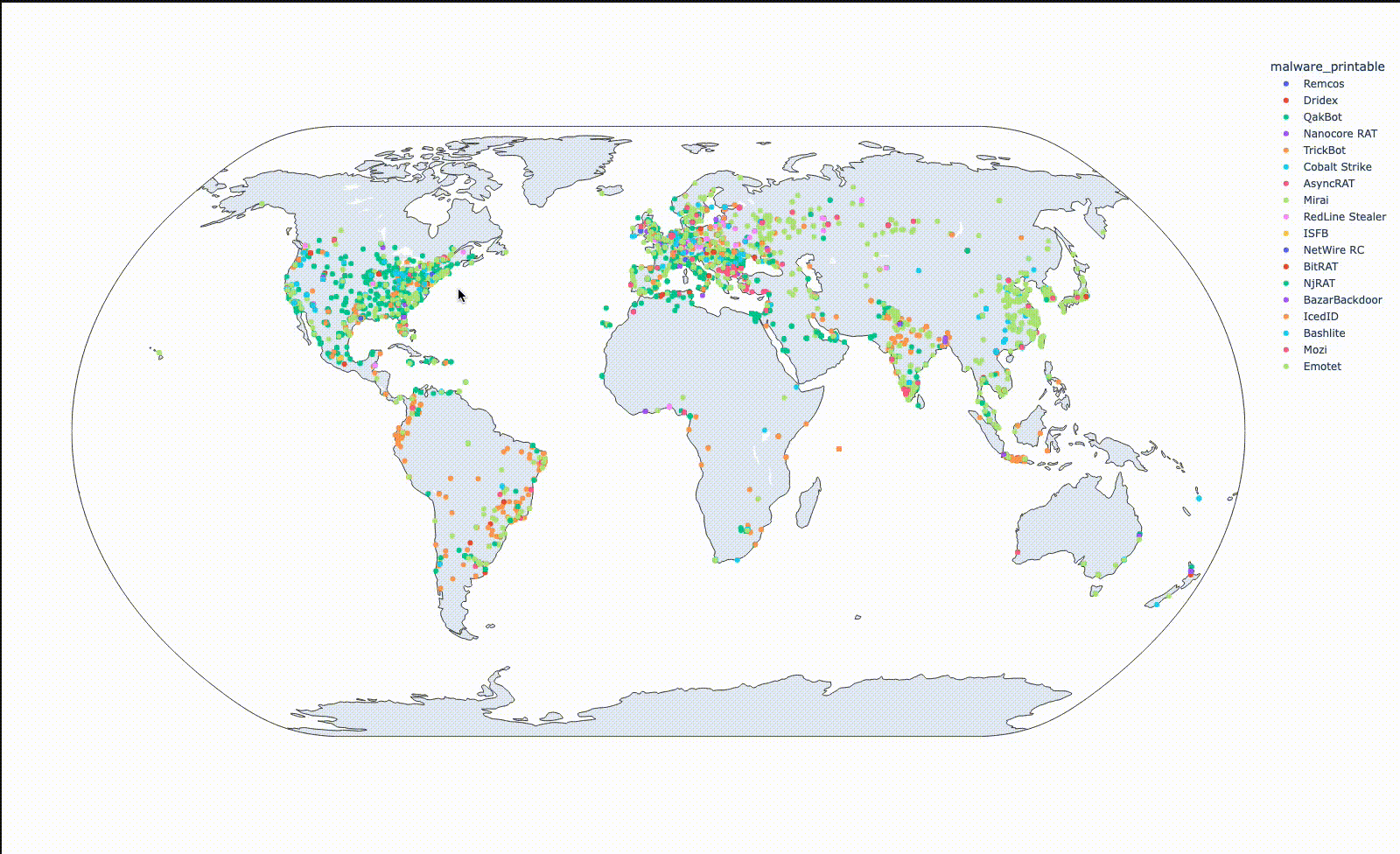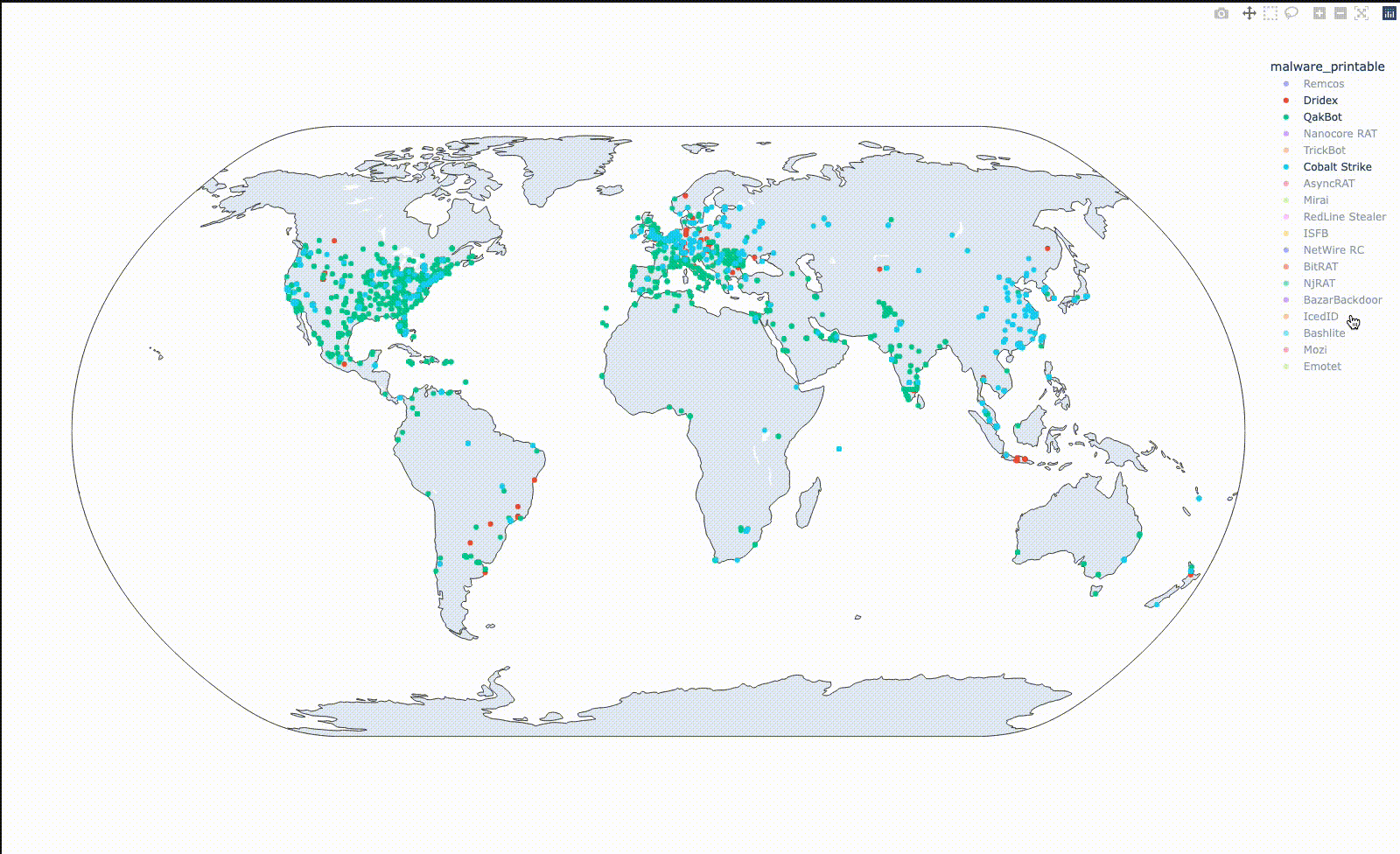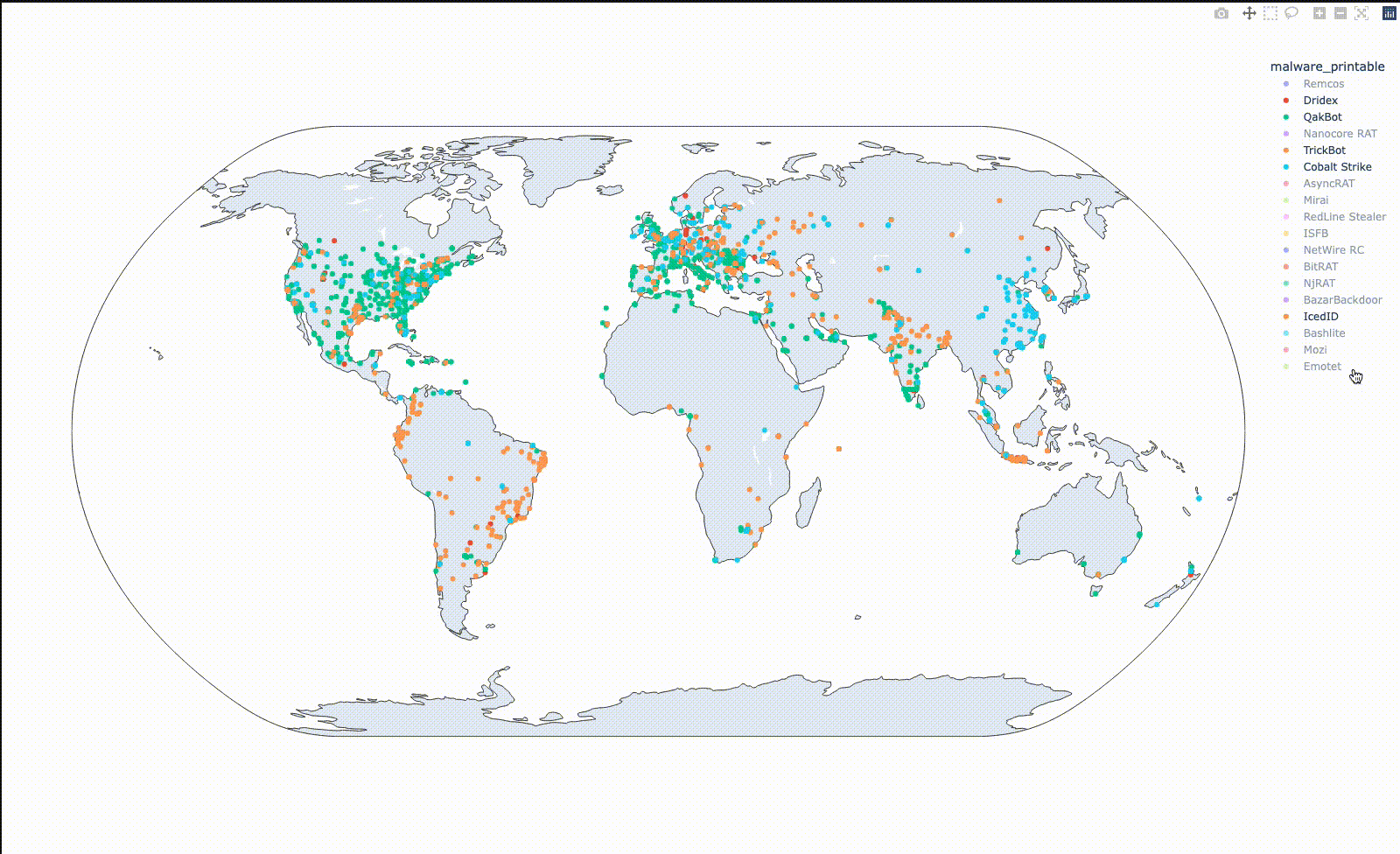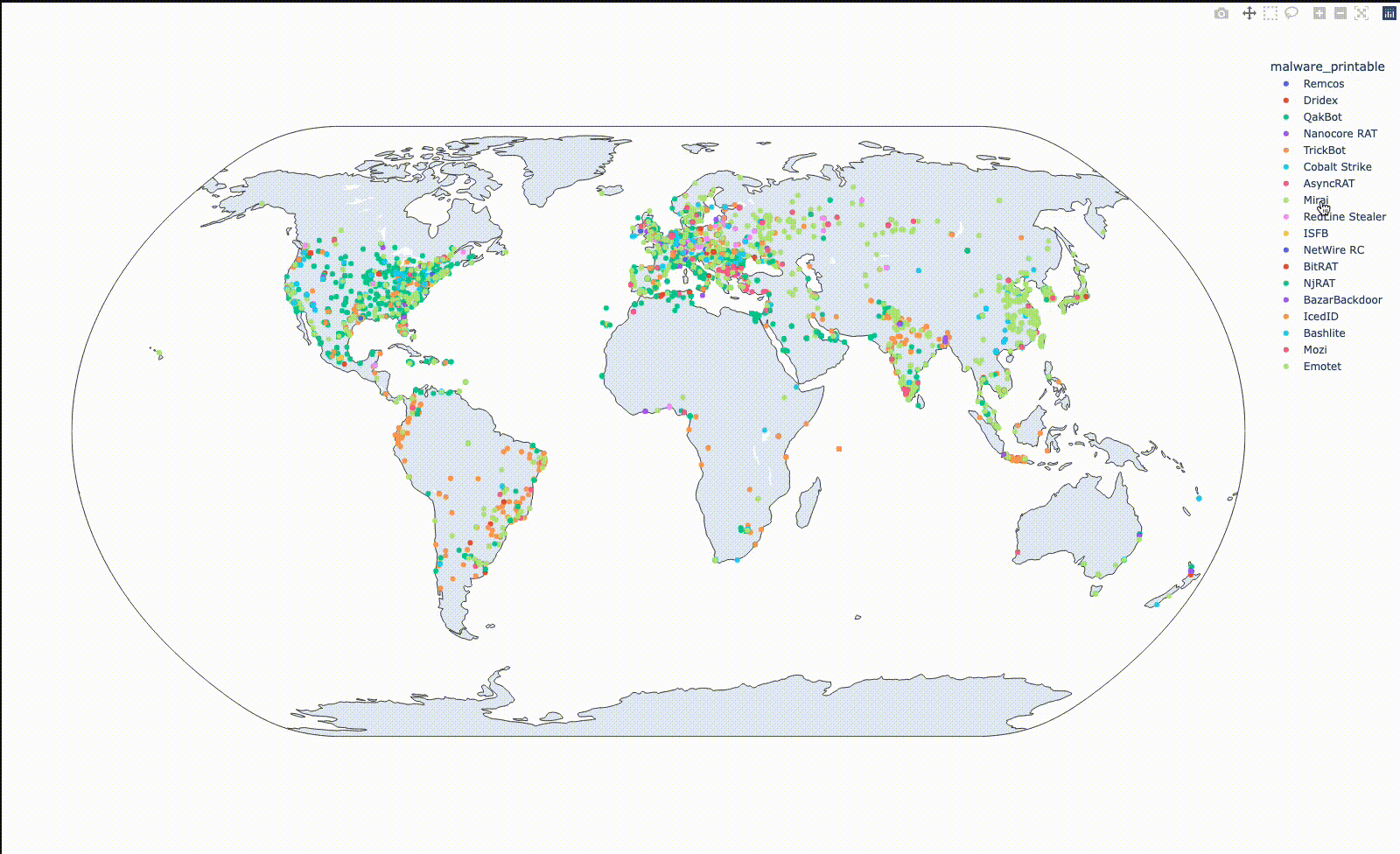
Qbotでは東海岸や欧州に分布の集中が見られ、TrickBotでは南米やインドネシアに集中が見られます。このように可視化してみると、 (少なくともthreatfoxに投稿されているデータについては) 意外と地域ごとの差がありそうな気がします。
気になったので、それぞれのIPアドレス、マルウェアファミリがどのASに属しているかも調べてみました。
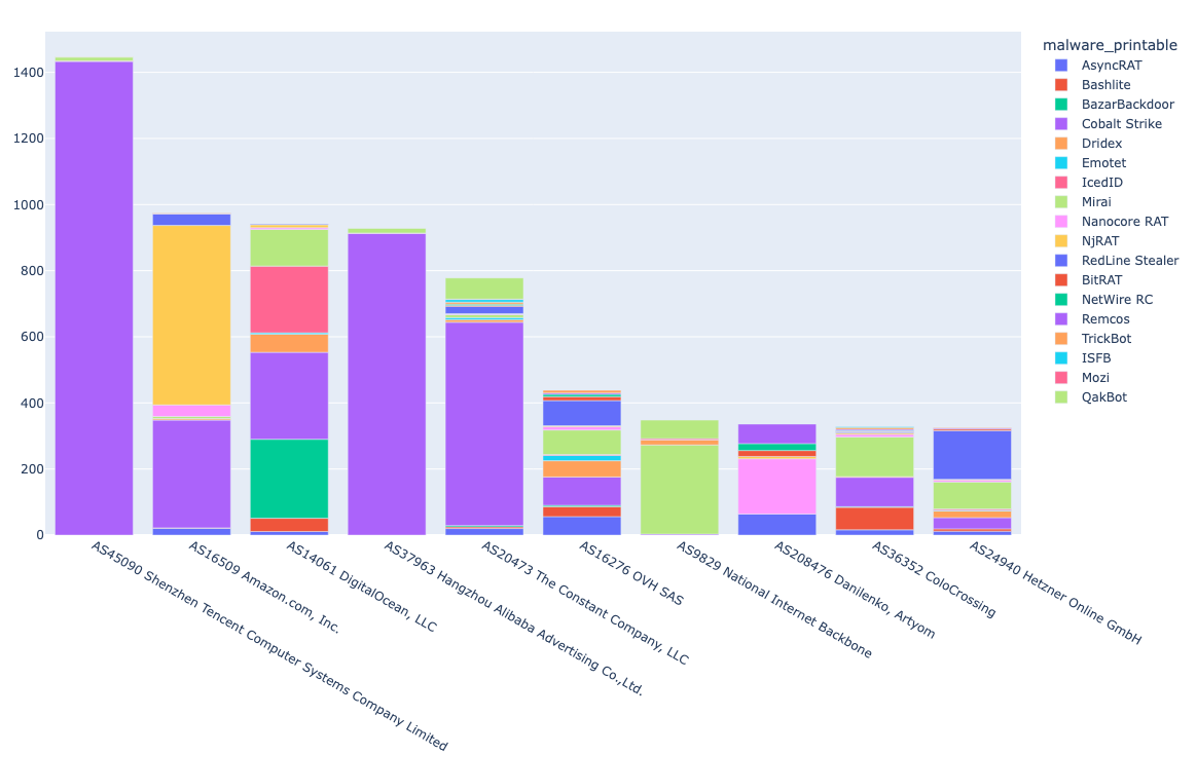
おまけ : 機械学習での分類を試みる
今ではサイバーセキュリティにおける機械学習の応用が広く話題になっています。今回の分析ではPythonのPandasで分析を行なっていますので、比較的簡単に機械学習での分類を試みることができます。そこで、ここまで収集したIPアドレスの情報を元に、IOC情報の示すマルウェアファミリを予測する分類器を作ってみたいと思います。悪性・良性の分類を行う場合は、別途良性(無害な)IPアドレスのデータセットが必要になります。
GeoLocation情報から入手した通信先の経度・緯度情報、AS、ISP、ポート番号などの情報に加え、先程の分析で知見を得られたポート番号についてさらに"possible_http(s)"という特徴量を追加しています。この特徴量は、ポート番号に「80」「443」を含むかどうか、という特徴量です。例えば「80」「8080」「10080」、「443」「8443」は我々の目から見るとそれぞれHTTP(S)通信を行なっていそうなポート番号ですが、数字的な距離は8000番以上離れていますので、それぞれが同じような意味を持つということを学習器が学習するのは難易度が高そうに見受けられます。このような人間目線での予備知識を補うため、新たに特徴量を追加
生成した上記データを学習器で学習します。学習用のデータと評価用のデータを分ける必要があるのですが、データをランダムにシャッフルして分割してしまうと、未来のデータをカンニングしながら過去のデータを予測する「リーク」が発生してしまいます。ですから、時系列順に並べたデータの前半85% (11月中旬までに投稿されたデータ) を学習データとし、後半のデータを評価用データとします。
評価用データを分類した結果、単純なAccuracy (正解率) は81%でした。また、各ファミリの分類結果は以下のようになりました。
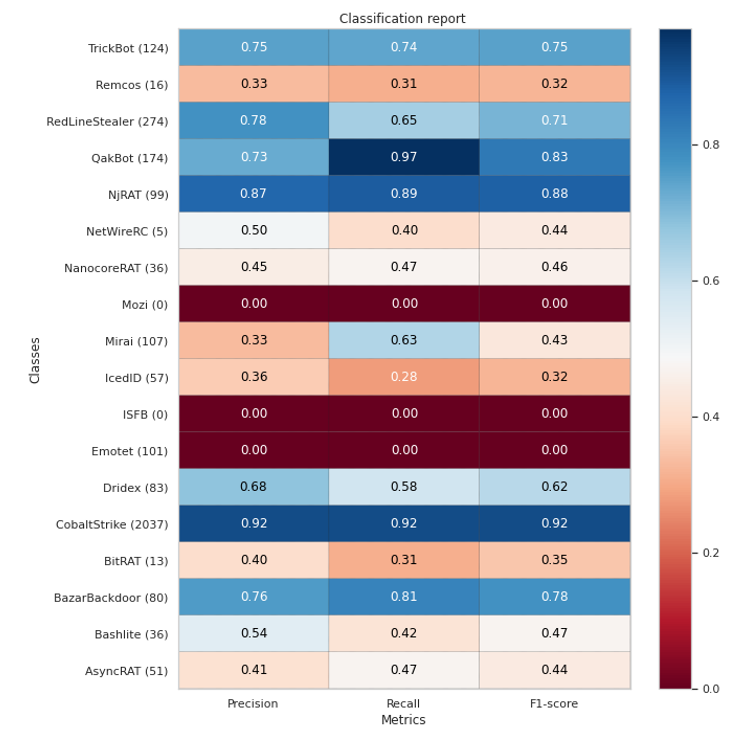
今回のデータで一番件数が多い「CobaltStrike」の分類精度は良いですが、それ以外のファミリの精度はあまりパッとしないものが多いですね。また、Emotetなど全く分類できていないファミリもあります。
機械学習とセキュリティの組み合わせは面白いこともあれば難しいこともあります。以下は私の考察です。
機械学習×セキュリティの面白さ
今回の分類器において、分類に使用した特徴量の重要度を示したグラフです。
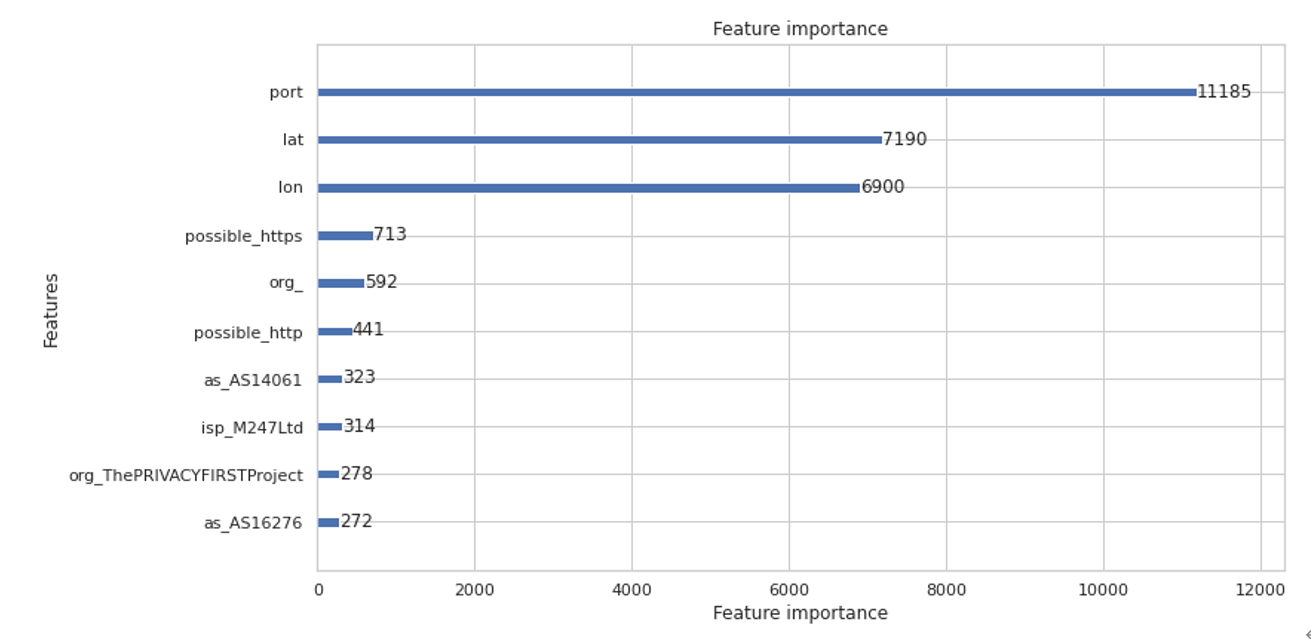
緯度、経度の情報が重要な特徴量として上位に出ています。より深い特徴量設計や分類手法の検討など、本格的な運用や精度向上を目指すとなるとやることは多いですが、今回のように簡易な分類であっても、良い着眼点を得ることが可能です。
また、作成した「80/443をポート番号に含むか」という特徴量も、重要度の上位に来ています。今回は簡単な例ですが、(セキュリティ)エンジニアとしての知見を反映できるのも、この手の分類の面白さだと思います。
機械学習×セキュリティの難しさ
一つ目は単純な精度の問題です。まだまだ検討や改良の余地はたくさんありますが、分析精度80%というのは実務で使用するのは正直難しい数値です。仮に精度が99%とかまで向上すれば補助的な役割として役立つ可能性があるかもしれません。しかし、精度が100%にならない限り、結局は最後に我々アナリストなど、人の目で見て白黒をつける必要があります。
二つ目に、機械学習器の構造的な問題として、クラス間のデータが不均衡だと、機械学習器の分類精度が落ちるという問題があります。今回の分類でも、少数派クラスの分類精度が怪しいのは結果から明らかですが、ここから悪性/良性判定をやろうとすると良性のものが圧倒的に多く、尚更難しくなります。
三つ目に、セキュリティは攻撃と防御のいたちごっこですから、時系列でデータが変化する点も難しいポイントの一つになります。例えば、Emotetは11月までの学習データ中にギリギリ出現しておらず、分類できませんでした。多くの機械学習による分類器は学習と予測を基本的には同時にできないので、あくまで近い将来の予測しかできません。またこのような知見を攻撃者側が入手すれば、誤検知を誘発するようなテクニックを使用してくることが目に見えています。
まとめ
今回のブログ記事では可視化を通じた脅威情報の分析例を紹介し、最後におまけで機械学習器による分類を試みました。PythonやPandasによる分析を行えば、少々手の込んだ集計や、外部データの取得も簡単にできます。また、可視化によって20,000件のテーブルデータから、様々な知見を得ることができました。さらに、今回紹介したPlotlyは、Dash[13]というPythonのWebフレームワークと連携します。痒い所に手が届くオリジナルのダッシュボードなども作れることでしょう。
参考
- https://techblog.security.ntt/102h5av
- https://www.nic.ad.jp/ja/materials/iw/2015/proceedings/s14/s14-abe.pdf
- https://pandas.pydata.org/
- https://abuse.ch/
- https://threatfox.abuse.ch/
- https://threatfox.abuse.ch/export/json/ip-port/full/
- https://plotly.com/python/
- https://feodotracker.abuse.ch/
- https://unit42.paloaltonetworks.jp/tutorial-qakbot-infection/
- https://techblog.security.ntt/102fvek
- https://ngrok.com/
- https://ip-api.com/docs/api:batch
- https://dash.plotly.com/
.png)